

Waterline Data was founded in 2013, and is backed by Menlo Ventures and Sigma West. The inspiration for the name “Waterline” came from the metaphor of the data lake where the data is hidden below the waterline. The mission of Waterline Data is to deliver a governed data lake to the business, and help data engineers and data scientists find the best suited and most trusted data without coding and manual exploration – in other words they should be able to “Hadoop above the waterline.” Waterline Data was developed to leverage the power and scalability of Hadoop to automate the cataloging and governance of data assets in the data lake, and enable secure self-service to find and understand the right data assets for data discovery.
Below is our interview with Oliver Claude, CMO of Waterline Data:
 Q: Oliver tell us something more about Waterline Data and your core competence?
Q: Oliver tell us something more about Waterline Data and your core competence?
A: Our product Waterline Data Inventory is an automated data inventory solution to find, understand, and govern data in Hadoop. The name Waterline was inspired from the metaphor of the data lake. As you know, one of the main benefits of a data lake is to be able to discover new business value from data assets quickly. But one important challenge with data lakes is, unlike a data warehouse, they don’t have a curated semantic layer that tells you what’s in the lake so you can find and understand the data you need. Without that metadata layer one has to “dive” into the lake to explore it – which defeats the purpose of quick time to value. Our mission is to bring the best and most trusted data to the user without having to “dive for it” – in other words bring the data to the waterline, and do so securely.
Related: Dasheroo – Makes Data Easier To Understand And Helps You Grow Your Business Faster
Q: How does Waterline Data differ from competition?
A: Let’s define the market in more detail.
First and foremost, we are focused on Hadoop. Within the Hadoop market, there are two primary areas of focus. One is data discovery and the other is data governance. It’s worth noting that they relate to each other, and I’ll address that later.
Data discovery itself is a fairly broad category, which encompasses different types of vendor products, from analytics suites like Datameer, to purpose-built tools like Trifacta, which focuses on data prep. The category of data discovery covers things like an inventory of the data in Hadoop, data prep to clean and format the data, the actual end-user tools to do visual analytics, and so on. The analytics suites are trying to do everything from the inventory to the analytics, while we’re seeing purpose built tools for some of the layers of the stack (e.g., Trifacta and Paxata for data prep).
We chose to focus on the foundational component of data discovery — the data inventory, which tells you what is in Hadoop. We felt that was key to enable an enterprise to go beyond pilot projects, such as analytics sandboxes, where a customer works with just a few files, to more of a data lake where the customer will deal with lots of data, where it isn’t possible to manually explore each file. Unlike the other tools which catalog only what a user has manually defined in the context of the tool, we take the opposite approach which is to catalog the entire lake automatically vs. one file at a time.
As I mentioned, data discovery and data governance are related. For example, if a user wants to mash together different data sets, data governance policies need to:
- Authorize that the user should have access to this data
- Mask any sensitive data from the user
- Provide an audit trail of what the user did for regulatory compliance.
Because data discovery and data governance are so intricately connected, we chose to incorporate data governance with our data inventory product, which the data discovery vendors don’t have. Furthermore, we have taken the approach of being complementary to what the Hadoop distributions are doing with regards to data governance, in order to deliver a seamless solution to customers. For example, we’re in the process of certifying with Hortonworks on Apache Atlas, we’re building integration to Cloudera Navigator, and we are a data governance partner of MapR and Pivotal.
In that respect, Waterline Data is unique in delivering an automated data inventory with data governance across any distribution and regardless of how many end-user tools will be used. So we give a customer ultimate flexibility to use any distribution, and either an analytics suite or a set of best of breed tools.
Related: Zefflin – State Of The Art Data Center Automation And Private Cloud Solutions
Q: Who is your ideal customer and why?
Our ideal customer is an enterprise that wants to build a data lake. As mentioned, we are ideal when a customer wants to go from “playing with Hadoop” to deploying a enterprise grade data lake where there will be a lot of data coming in that the different business units are going to want to leverage in more of a self-service manner. That means being able to:
- Find the best-suited data quickly
- Be notified of new data based on schema changes
- Make sure data governance policies are implemented seamlessly
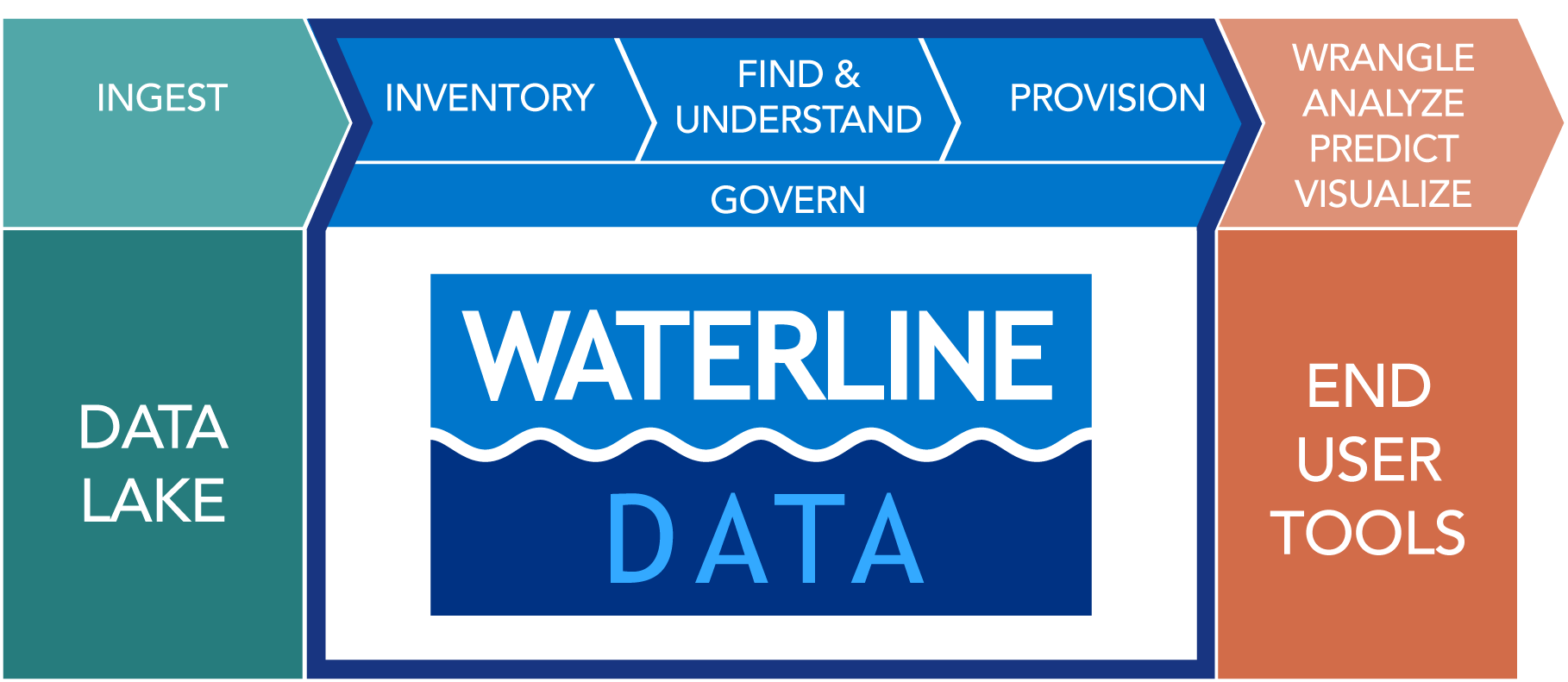
Q: What are main benefits of your automated data inventory product?
1) We enable IT to deliver a business-ready data lake
◦ Automation allows IT to keep up with the demand for data – data is always “fresh” and available for self-service
◦ “Built-in” data governance enables IT to deploy a “governed data layer” so self-service use of the data is done in compliance with security and data governance policies
◦ Business is updated in “real-time” with changes and updates to the data – for instance schema changes are detected and impact analysis can be understood right away
2) We help accelerate data prep
◦ 80% of data prep is “finding” the right data – we automate that part of the process with a complete catalog of data assets
◦ We pre-compute a data quality assessment for all the data assets – data engineers or data scientist can inspect the data at a glance before they invest precious time wrangling and modeling the data so they don’t end up wasting time debugging later on
◦ We enable crowdsourcing and re-use – data scientists and data analysts can tag and annotate the data to document their findings and to enable future re-use in other projects
3) We help prevent data discovery “sprawl” with a governed data lake
◦ We discover sensitive data so it can be protected – we help ensure sensitive data can be protected before users point the plethora of data discovery tools to the data
◦ We provide a single point to manage metadata for Hadoop –we empower data stewards to “curate” the metadata before opening up the lake to the users
◦ We discover data lineage and audit the data inventory across Hadoop – we provide a cross view of data lineage and audit regardless of how many data discovery tools are in use
Related: TrepScore – Data Management System Designed For Startups
Q: How would you convince the reader to start using your services?
A: I’m reminded of a statement made by an enterprise BI executive, “We have 100 million columns of data in our company — how can anyone find anything?”
In the age of the Internet of Things, the potential to lose control of data assets has never been more serious. As Hadoop is playing a bigger and bigger role in providing the place to bring a lot of the data together, we believe we are providing an essential capability to help enterprises know what data assets they have, what people have discovered already, and allow new discovery to be made on top, and do so in a self-service manner with data governance compliance.
Activate Social Media: