

The value proposition of becoming a data-driven business is clear with expectations of increased revenues, bigger margins, and new business opportunities. But one of the biggest obstacles companies face is the separation of data sources. One of the leading Hadoop vendors, MapR, has developed a converged data platform that eliminates separate data silos and provides a common platform for file, tables, streams, and other unstructured data to usher in a new generation of big data applications.
Below is our interview with Jack Norris, SVP, Data & Applications at MapR. With over 20 years of enterprise software marketing experience, Jack drives understanding and adoption of new applications enabled by data convergence.

Q: What changes are happening in enterprise computing today that are making businesses rethink their architectures?
A: Businesses are being revolutionized and new ones are being formed based on converged data, incorporating analytics at scale and making real-time adjustments to improve business performance. This is a major change. For the last few decades, the accepted best practice has been to keep operational and analytic systems separate, in order to prevent analytic workloads from disrupting operational processing. Existing applications and typical analytic solutions dictate separate data formats. The resulting silos proliferate throughout a company completely separated from production systems. Analytic silos introduce time delays in the process, add complexity and may result in “multiple versions of the truth”.
Q: What direction is technology architecture headed based on these changes?
A: Inevitably, the direction of technology architecture is towards a limitless distributed model based on a converged data that will serve a flexible compute stack composed largely of open source technologies like Apache Hadoop, Spark, Mahout, Drill, etc.; but also serve a wide array of commercial products used by companies to gain additional insight. This is what CIOs and Enterprise Architects see on the distant horizon: a completely automated, agile and integrated development and deployment platform that gets the most value for every dollar spent. It’s important to understand the inherent confusion when describing a converged data platform that relies on distributed platform. For instance, the converged data center requires data to be processed where it is most (cost) effective. That data may be in your primary data center, or on the manufacturing shop floor, or in the cloud, or it may be flowing from an ocean of sensors and smart devices to aggregation points and then multiple data centers. Or, there may be data that you don’t currently own, but desperately need to incorporate into the process – like social data that can tell you how your customers feel about your products or services. That means even small companies can be big data companies, and can benefit from converged data.
 Recommended: Cyber adAPT Brings Post-Compromise Forensics To Advanced Detection
Recommended: Cyber adAPT Brings Post-Compromise Forensics To Advanced Detection
Q: What keeps us from always making decisions in real time?
A: Typically, the limitations of our existing systems and architectures are the biggest obstacles which slow down the ability to drive real-time decisions. For example, extract/transform/load (ETL) processes required for particular applications or for processes dependent on getting relevant data to analysts. Many processes especially big data platforms require batch processing methods. Operational data is extracted from sources like relational databases and text files, transformed into a common format that analytics tools can handle, and then loaded into the analytical database or warehouse for decision support analysis.
This process can take hours. In fact, because of the need for human involvement, it often takes days. By the time managers get reports the information is out of date. That has business consequences. For example, if the analytics indicate that a potential security breach, but the pattern doesn’t resemble any known exploit it might take hours or days for analysts to diagnose and determine the corrective action. This is why a converged data platform approach can eliminate the delays associated with silos and can provide a platform to perform automated analytics and machine learning processes to drive real-time results. In the case of an unknown security breach we see customers move resolution times down to minutes.
Q: Why can’t Apache Hadoop, a freely available big data management system, solve the data convergence opportunity by becoming a master data repository for the enterprise?
A: Hadoop—and more specifically the Hadoop Distributed File System (HDFS)— is a write-once, batch oriented storage layer that lacks enterprise class protection against data corruption, disaster recovery features, and the ability to perform point-in-time consistent snapshots. So without a convergence of enterprise storage and Hadoop, HDFS cannot serve as a system of record for the long-term safe storage of data. The batch limitations of HDFS make it inappropriate to converge real-time database operations and streaming support on the same platform. So when using Apache Hadoop and other commercial distributions you end up with massive amounts of data in a Hadoop cluster, massive amounts of data in a NoSQL database cluster, a separate cluster for streaming data (Kafka); several new technology silos that must be negotiated by IT ops, architects, and developers.
Q: What are some of the benefits of a converged architecture and who is using them?
A: A converged platform accelerates value from emerging open source technologies by reducing latency and providing common governance, security, and data quality as well as for enterprise readiness. A platform that enables a single investment to support workloads across all of these can also future proof organizations so they can exploit the next innovations that will appear. Applications that leverage these open source projects with converged data are being used across industries and business functions, including:
• Retailers that adjust the online experience of users including product recommendations, customized advertising, and dynamic pricing
• Manufacturers that leverage machine sensor data to identify quality issues and adjust the manufacturing process
• Telecom providers enhancing mobile services, expanding cloud offerings, and improving services
• Advertising technology companies driving continued growth and integrating global operations
Recommended: KeepCalling – International Calls Made Easy!
Q: So what is the right approach?
A: Start with the data. The promise of big data is to gather information into a centralized hub or data lake and bring processing to it. When it’s time to get serious there are two key areas to focus upon. The First Key is Convergence. A Converged Data Platform eliminates separate clusters and enables applications to benefit from all data. In a converged data platform all data is treated like first class citizens –structured, unstructured, data in motion and data at rest. The platform enables diverse applications batch and continuous all in the same platform. A Converged Data Platform eliminates separate clusters and enables applications to benefit from analytics in real time.
The Second Key is event-based data flows. Examples of data flow include web events, machine sensors, and biometric data. Operational agility requires flowing data to be quickly analyzed and understood in context. Context is derived from understanding long-term trends and patterns as well as leverage newly arriving data. Data-in-motion is integrated directly with data-at-rest.
Q: Why is the addition of Streaming so important to convergence?
A: When discussing big data we tend to focus on the end state–the massive scale and variety of data required to cost effectively manage, analyze, and protect data. But big data is created one event at a time, whether it is from sensors, log files, or customer interactions. Streaming makes it possible to better manage, analyze and distribute these events across locations and subscribers. We’re talking up to billions of messages per second, millions of data sources, and over hundreds of locations.
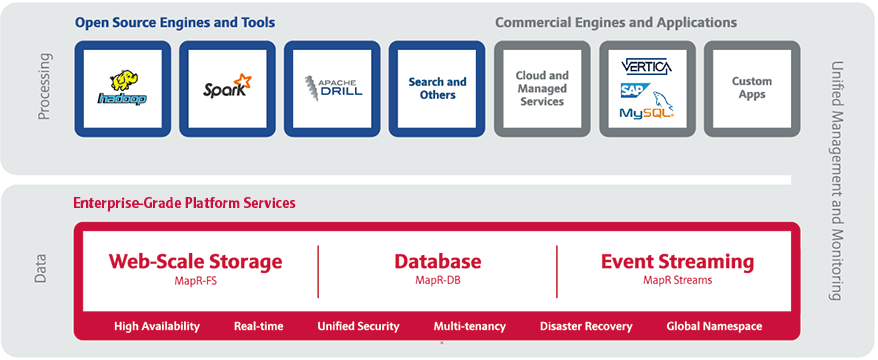
Q: Tell us about the MapR Converged Data Platform
A: The MapR Converged Data Platform integrates Hadoop and Spark with real-time database capabilities, global event streaming, and scalable enterprise storage to power a new generation of big data applications. The MapR Platform delivers enterprise grade security, reliability, and real-time performance while dramatically lowering both hardware and operational costs of our customers’ most important applications and data.
 Recommended: MCN Healthcare Transforms Legacy Policies To Cloud-Based Policy Management Solutions
Recommended: MCN Healthcare Transforms Legacy Policies To Cloud-Based Policy Management Solutions
Q: How has the MapR Converged Data Platform fit into your vision?
A: From day one, our vision has been to build the best data platform in the world. We initially introduced platform innovations for Hadoop, greatly improving its reliability, performance, and ease of use. We invested heavily in our underlying architecture so that we could deliver advanced capabilities that build on the power of our existing platform, while at the same time contributing to and supporting the open source ecosystem as well as industry standards.
We’ve been steadily executing on this vision ever since, converging the core platform services and engines required for modern data-driven applications. Our rich history of data convergence began with our initial launch of the MapR Platform that combined Hadoop, the best of open source innovation and advanced enterprise storage capabilities. In 2013, we followed up by converging NoSQL data capabilities into the platform. We followed this by pioneering and contributing to Apache Drill. Our vision at MapR is to deliver a data platform for organizations to gain a competitive advantage and drive their business results by impacting business as it happens. This requires a data platform that supports the widest variety of data processing, analytics and applications to enable organizations to integrate analytics into their operations.
Activate Social Media: