

Dremio has a vision to provide a self-service model for analysts and data scientists to access any data, at any size at any time, all through the most powerful and widely adopted standard for data analytics: SQL. Data scientists and analysts can join data across disparate sources such as NoSQL, relational, using their favorite visualization tool (eg, Tableau) or data science technology (eg, Python). Data Fabric is more than just accessing the data – it’s also about making queries fast, no matter how big the data. Simply said, Dremio puts data directly in the hands of analysts and data scientists, from any source and at any scale, while preserving governance and security. The company’s simple and intuitive interface empowers business users to discover, curate, and share data for their specific needs, without burdening IT. Below is our interview with Tomer Shiran, Co-Founder and CEO of Dremio:

Q: What realities are facing business analysts and data scientists today making it difficult for them to gain insights from the volumes of data supposedly at their fingertips?
A: Analyzing modern data is extremely challenging. Organizations struggle with extracting data from a variety of different data sources and loading it into the data warehouse. Today, data is increasingly stored outside of RDBMSs, but existing BI connectors provide a poor user experience and traditional ETL into a centralized data warehouse doesn’t work. In fact, it’s a great time to be a developer – you can download MongoDB, HBase, Elasticsearch, Hadoop – all very scalable, open source, free, great APIs – to build apps fast. However, for business analysts and data scientists, life isn’t so great. They can’t connect their BI tools like Tableau, Qlik, Power BI to these data warehousing systems like Teradata and Vertica. It’s too slow and too hard. So, they end up spending 90% of the time finding, reshaping, and copying data rather than analyzing it. Centralizing all their data from varied data warehouses to use Tableau, and the other BI connector tools is painful for IT and data engineering. For example, adding a column to their data warehouse can take many months and millions of dollars. In addition, the data is stale and summarized and often not what was requested anyway. Despite promises of software designed to unlock the value of data, analysts and data scientists continue to struggle to harness data for business intelligence and data science.
Q: Is self-service analytics really new?
A: While some vendors have brought self-service to BI, the rest of the analytics stack is still IT-driven, especially when it comes to modern data sources. Analysts and data scientists are still entirely dependent on IT to source and reshape data for their needs, and they are still dependent on whatever query processing resources IT has set up for them to run their analysis. We think that the self-service model needs to encompass the entire analytics stack.
 Recommended: Demisto – Taking On Incident Response With Machine Learning & Automation
Recommended: Demisto – Taking On Incident Response With Machine Learning & Automation
Q: Tell us about Dremio. Where do you come in?
A: Working with existing data sources and business intelligence tools, Dremio eliminates the need for traditional ETL and data warehousing. Dremio combines consumer-grade ease-of-use with enterprise-grade security and governance, and includes ground-breaking execution and caching technologies that dramatically speed up queries.
Dremio also provides a future proof strategy for data, allowing customers to choose the best tools for their analysts, and the right database technology for their apps, without compromising on their ability to leverage data to drive the business. Because Dremio can be run in a dedicated cluster, in the cloud or on prem, or as a service provisioned and managed in a Hadoop cluster, customers can easily scale Dremio to meet their needs at any scale.
Q: How is Dremio different from business intelligence tools?
A: Dremio makes BI tools better. Unlike traditional approaches, which require building a data warehouse or rely on point to point single server designs, Dremio connects any analytical process (eg, BI tools) to any data source and scales from one to 1000 plus servers, running on dedicated hardware or in a Hadoop cluster.
With Dremio business users can perform critical data tasks themselves, without being dependent on IT. To that end, we don’t compete with business intelligence vendors, we partner with them. Companies like Tableau brought self-service to BI. We bring self-service to all the other layers of the analytics stack, including ETL and data warehousing, which are entirely IT-driven today.
Customers can easily discover data from a comprehensive catalog, work together as teams to curate and share virtual datasets, and run analytical jobs through Dremio from any BI or data science tool.
Q: How are your customers using Dremio?
A: Dremio Data Fabric is being used by leading organizations in the US, Europe, Asia, and Australia, such as Daimler, a leading producer of premium cars and the world’s largest manufacturer of commercial vehicles, Intel, the world’s largest semiconductor chip maker; and OVH, Europe’s leading cloud provider.
Because Dremio can be run in the cloud, on-premises, or as a service provisioned and managed in a Hadoop cluster – customers can easily deploy Dremio to meet their needs at any scale. Popular use cases include BI on Modern Data, like Elasticsearch, S3, and MongoDB; Data Acceleration, making even the largest datasets interactive in speed; Self-Service Data, making consumers of data more independent and less reliant on IT; and Data Lineage, tracking the full lineage of data through all analytical jobs across tools and users.
 Recommended: Distillery Brings A Balance Of Expertise And Creativity Through Software Design And Development Services
Recommended: Distillery Brings A Balance Of Expertise And Creativity Through Software Design And Development Services
Q: What are some examples of the key capabilities of the Dremio Data Fabric solution?
A: Key capabilities in Dremio Data Fabric include:
● Apache Arrow Execution Engine. Dremio is the first Apache Arrow-based distributed query execution engine. This represents a breakthrough in performance for analytical workloads as it enables extreme hardware efficiency and minimizes serialization and deserialization of in-memory data buffers between Dremio and client technologies like Python, R, Spark, and other analytical tools. Arrow is also designed for GPU and FPGA hardware acceleration, making it a powerful paradigm for machine learning workloads.
● Native Query Push Downs. Instead of performing full table scans for all queries, Dremio optimizes processing into underlying data sources, maximizing efficiency and minimizing demands on operational systems. Dremio rewrites SQL in the native query language of each data source, such as Elasticsearch, MongoDB, and HBase, and optimizes processing for file systems such as Amazon S3 and HDFS.
● Dremio Reflections™. Dremio accelerates processing and isolates operational systems from analytical workloads by physically optimizing data for specific query patterns, including columnarizing, compressing, aggregating, sorting, partitioning, and co-locating data. Dremio maintains multiple reflections of datasets, optimized for heterogeneous workloads that are fully transparent to users. Dremio’s query planner automatically selects the best reflections to provide maximum efficiency, providing a breakthrough in performance that accelerates processing by up to a factor of 1000.
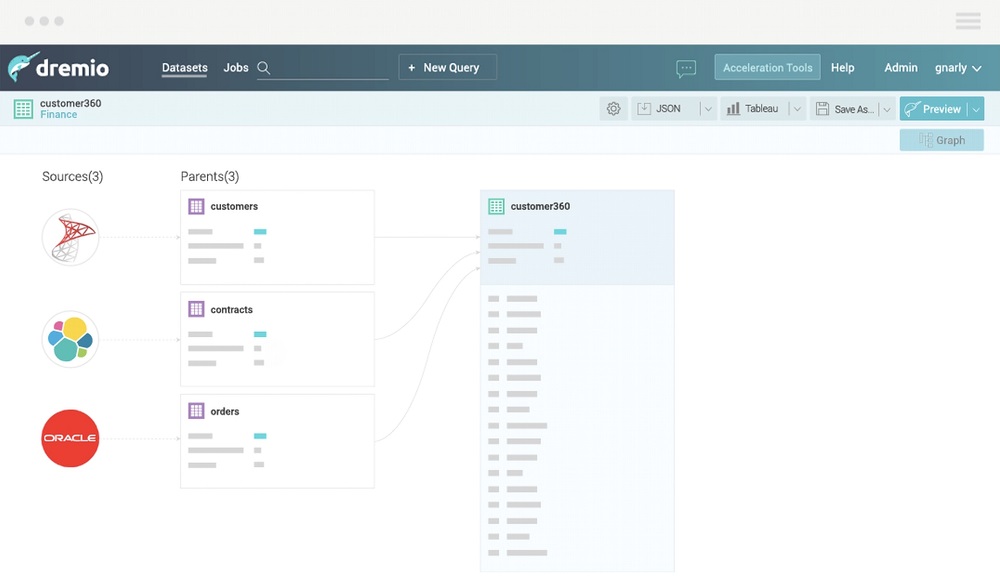
● Comprehensive Data Lineage. Dremio’s Data Graph preserves a complete view of the end to end flow of data for analytical processing. Companies have full visibility into how data is accessed, transformed, joined, and shared across all sources and all analytical environments. This transparency facilitates data governance, security, knowledge management, and remediation activities.
● Self-Service Model. Dremio was designed with analysts and data scientists in mind, providing a powerful and intuitive interface for users to easily discover, curate, accelerate, and share data for specific needs, without being dependent on IT. Users can also launch their favorite tools from Dremio directly, including Tableau, Qlik, Power BI, and Jupyter Notebooks.
● Built for the Cloud. Dremio was designed for modern cloud infrastructure, and is able to take advantage of elastic compute resources as well as object storage such as Amazon S3 for its Reflection Store. In addition, Dremio can analyze data from a wide variety of cloud-native and cloud-deployed data sources.
Q: Can you talk about security and governance of the product?
A: Dremio captures user metadata and behavior to make smart data recommendations, and integrates with enterprise security controls like LDAP and Kerberos. Now businesses can embrace self-service without compromising security or data governance. Dremio combines enterprise-grade security and governance with a powerful and intuitive access control. Users can decide who can access data down to the row and column level. They can even mask the data for some users/groups. Since the datasets are connected, users can browse the ancestors and descendants of each dataset and column. For auditing purposes they can see who’s accessing what data and when. Real-time reports can include the top 10 users of a given dataset, off-hours access, etc.
Q: How can I get Dremio?
A: Dremio is open source, distributed as a Community Edition, which is free for anyone, as well as an Enterprise Edition, which is available as part of an annual subscription with support, a commercial license, and enterprise features. Dremio is immediately available for download on our website.
Activate Social Media: